
Introduction
We present simple illustrations, explanations and proofs for two very important theorems,
- the probability integral transformation, and,
- the quantile function theorem.
Both theorems are important in statistics, computational math, machine learning and beyond.
We shed light on the background of these two well-known theorems by investigating the “why-it-works” question. To this end, we take a closer look into the difference between continuous and discrete distributions with respect to both theorems. For instance, we demonstrate why the Probability Integral Transformation Theorem in general does not work for discrete distribution.
In addition, we also outline under what circumstances a discrete distribution at least “converges towards the assertion” of the Probability Integral Transform Theorem. It will become clear what is meant by that in the course of the post.
Let us first state the actual theorems in the next section.
Afterwards, we are going to illustrate both theorems by example and finally we prove them by using Angus [1.] ideas. Note that we will also show why many ‘proofs’ provided in textbooks or internet resources are not complete and rather misleading.
We will also apply the derived theory by generating normally distributed samples in Microsoft Excel. At last, we provide an overview on the connection to the concepts of copulas for the multi-dimensional case.
Theorems
Let  be a real-valued random variable defined on a probability space
be a real-valued random variable defined on a probability space  . Let
. Let ![F: \mathbb{R} \rightarrow [0,1]](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-68d7731d9b74f4d373b7ad2dee1f9e8d_l3.png "Rendered by QuickLaTeX.com") be defined by
be defined by  with
with  be the distribution function of .
be the distribution function of .
Theorem I (Probability Integral Transformation):
If has distribution function  which is continuous, then the random variable
which is continuous, then the random variable  has the distribution function of
has the distribution function of  .
.

The second theorem that we are going to prove is as follows.
Theorem II (Quantile Function):
Let be a distribution function. If ![F^{-1}: \ ]0,1[ \rightarrow \mathbb{R}](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-b17116f0a19e412df96cb0715d82b2ac_l3.png "Rendered by QuickLaTeX.com") is defined by
is defined by  ,
,  and
and  has the distribution of , then
has the distribution of , then  has distribution function .
has distribution function .
Note that the distribution function in Theorem I needs to be continuous while the distribution function in Theorem II can also be discrete.
Why are both theorems considered to be so important?
Whenever simulations are required, the Quantile Function Theorem is of importance as it is the basis to generate samples of probability distributions. The Probability Integral Transformation Theorem is the basis for many statistical tests (this is an important field of Frequentist’s statistics) and the definition and/or interpretation of a copula. Moreover, both theorems are interrelated to each other as we will see in the proofs.
Both theorems are fundamental results that are applied in many important areas and it is definitely worth understanding them. Let us now try to understand what the theorems actually state by considering examples.
Illustrations
Probability Integral Transformation
Let us draw a large sample  distributed by the standard normal distribution. We can use a computer and R, for instance, to perform that kind of task.
distributed by the standard normal distribution. We can use a computer and R, for instance, to perform that kind of task.
X <- rnorm(n=10^6, mean=0, sd=1) hist(X)
A simulated sample of a standard normally distributed random variable is shown in the next Fig. 1.

If we now apply the corresponding distribution function ![F:\mathbb{R}\rightarrow [0,1]](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-27df4b5a3263fd3c6d7228c3a650d1af_l3.png "Rendered by QuickLaTeX.com") of the standard normal distribution to the output of the random variable , we get
of the standard normal distribution to the output of the random variable , we get  which is clearly governed by the uniform distribution on
which is clearly governed by the uniform distribution on ![[0,1]](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-0621f04d8a0d9e76a5abce6204d5b435_l3.png "Rendered by QuickLaTeX.com") as we can see in the next histogram in Fig. 2.
as we can see in the next histogram in Fig. 2.
Again, we use a computer and R to perform also the second step.
Y <- pnorm(X, mean=0, sd=1) hist(Y)
Realize that the range of any distribution function is , which equals the domain of any random variable governed by .
![Histogram of Uniform Distribution on [0,1]](https://www.deep-mind.org/wp-content/uploads/2020/10/Rplot.png)
 and its distribution function , i.e.
and its distribution function , i.e. The demonstrated effect is not a coincidence but based on the Probability Integral Transform Theorem. That is, we could set to be governed by any continuous random variable and the result would always be the same. For continuous random variables, the distribution function is a monotonically non-decreasing continuous function. In general, the distribution function of a continuous random variable does not need to be strictly increasing. For instance, the continuous uniform distribution function and the trapezoidal distribution function are not strictly increasing.
Let us do the simulation again with the exponential distribution and with the Cauchy distribution. Both do have a continuous distribution function.
X <- rexp(n=10^6, rate = 1) hist(X) Y <- pexp(X, rate=1) hist(Y)
X <- rcauchy(n=10^6, location=0, scale=1) hist(X) Y <- pcauchy(X, rate=1) hist(Y)
You will notice that similar outputs as in Fig. 2 are generated, which indicates that  .
.
If you even want to test more distributions you can pick one of the list of continuous distributions provided that you can find corresponding packages in R.
If we do the same exercise with a discrete random (i.e. not continuous) variable such as the Binomial distribution ( = sequence of independent Bernoulli experiments,
= sequence of independent Bernoulli experiments,  = relative frequency of successes = probability),
= relative frequency of successes = probability),  the resulting histogram is quite different. Note that we denote the discrete distribution function of by
the resulting histogram is quite different. Note that we denote the discrete distribution function of by  .
.
Example 1 (Binomial Variable)
Let us consider the case with  . A binomial distribution
. A binomial distribution  consists of independent trials with a success rate for each trial. Hence, in our specific example we have the situation as outlined in Tab. 1.
consists of independent trials with a success rate for each trial. Hence, in our specific example we have the situation as outlined in Tab. 1.
| 1. Bernoulli Trial | 2. Bernoulli Trial |
| Success | Success |
| Failure | Failure |
| Success | Failure |
| Failure | Success |

That is, the basic set  consists of a sequence of Bernoulli outcomes represented by corresponding -tuples. Thus,
consists of a sequence of Bernoulli outcomes represented by corresponding -tuples. Thus,  failure,failure
failure,failure success,failurefailure,successsuccess,success
success,failurefailure,successsuccess,success is the basic set of this example.
is the basic set of this example.
Let us simulate the Binomial variable as defined above by using a computer and R.
X <- rbinom(n=10^6, size=2, prob=0.5) hist(X) Y <- pbinom(X, size=2, prob=0.5) hist(Y)
The corresponding histogram of binomial variable can be seen in Fig. 3.
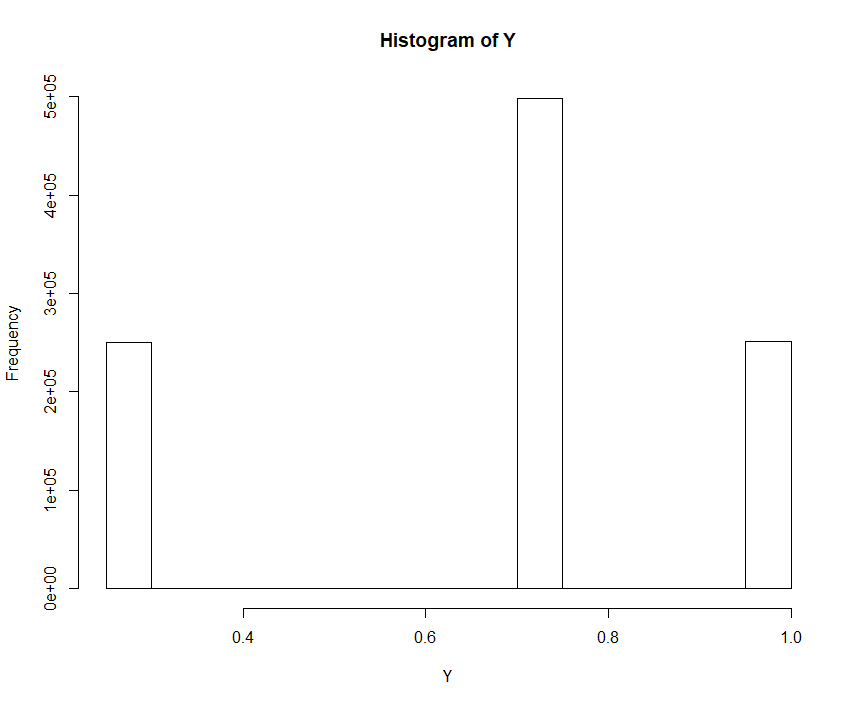
 with . The parameters are set to
with . The parameters are set to  independent Bernoulli experiments with success rate
independent Bernoulli experiments with success rate Without continuity the controlled correspondence between an element of the domain and the image ![F(x)=:u\in [0,1]](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-8f9db4c5f3591f086bf65b2940aa9003_l3.png "Rendered by QuickLaTeX.com") gets lost. The corresponding discrete distribution function is defined as depicted in Fig. 4.
gets lost. The corresponding discrete distribution function is defined as depicted in Fig. 4.
 of
of Failure for both trials occur in one out of four possible cases, i.e., with probability  . There are two ways to get one success and one failure, i.e., with probability
. There are two ways to get one success and one failure, i.e., with probability  . Two successes in a row occur with probability . Putting these pieces together one ends with the above discrete distribution function of shown in Fig. 4.
. Two successes in a row occur with probability . Putting these pieces together one ends with the above discrete distribution function of shown in Fig. 4.
Let us consider how this is reflected in the R simulation. To this end, we use the table command in R:
X <- rbinom(n=10^6, size=2, prob = 0.5) table(X) Y <- pbinom(X, size=2, prob = 0.5) table(Y)
We can see that the R variable contains about 25% of  s, about 50% of
s, about 50% of  s and about 25% of
s and about 25% of  s. The R variable (containing these figures) is then entered into the distribution function , which translates that input into accumulated probabilities
s. The R variable (containing these figures) is then entered into the distribution function , which translates that input into accumulated probabilities  . Hence, we get about 25% of
. Hence, we get about 25% of  , about 50% of
, about 50% of  and about 25% of
and about 25% of  . This equals exactly the output of the histogram in Fig. 3.
. This equals exactly the output of the histogram in Fig. 3.
Ultimately, the Probability Integral Transformation cannot work for Example 1 (Binomial Variable) since the increase of the discrete distribution function values are not even (i.e. ‘uneven jumps’). In this specific case, we have an increase of two times 0.25 and one time 0.5.
In continuous distribution functions these increases behave in a controlled manner and the distribution function balances the likelihood of events with the corresponding pace of the accumulation. For instance, the simulated standard normal distribution as shown in Fig. 1 contains only few samples in the tail left of -3. This, however, is compensated by the almost flat distribution function curve of the standard normal distribution around the area of -3. This has the effect that a wider range of the domain of is needed to fill up the corresponding probability bucket of the uniform distribution. Note that in Fig. 2, for instance, this probability bucket comprises  since 20 buckets have been used to cluster the entire probability mass of 1.
since 20 buckets have been used to cluster the entire probability mass of 1.
Example 2 (Binomial Variable)
The binomial distribution converges towards a normal distribution if we increase the number of trials (in R it is called the size). This implies that the ‘uneven jumps’ of a discrete Binomial distribution are getting less and less meaningful. Indeed, if we repeat a simulation as follows the result looks quite promising:
size <- 10^5 X <- rbinom(n=10^6, size=size, prob = 0.5) hist(X) Y <- pbinom(X, size=size, prob = 0.5) hist(Y)
So, if we change the size from  to
to  , we get the following histograms shown in Fig. 5 to Fig. 7. Apparently, the approximation of , that is governed by the binomial distribution, to the normal distribution ultimately implies the approximation of
, we get the following histograms shown in Fig. 5 to Fig. 7. Apparently, the approximation of , that is governed by the binomial distribution, to the normal distribution ultimately implies the approximation of  toward the standard uniform distribution:
toward the standard uniform distribution:
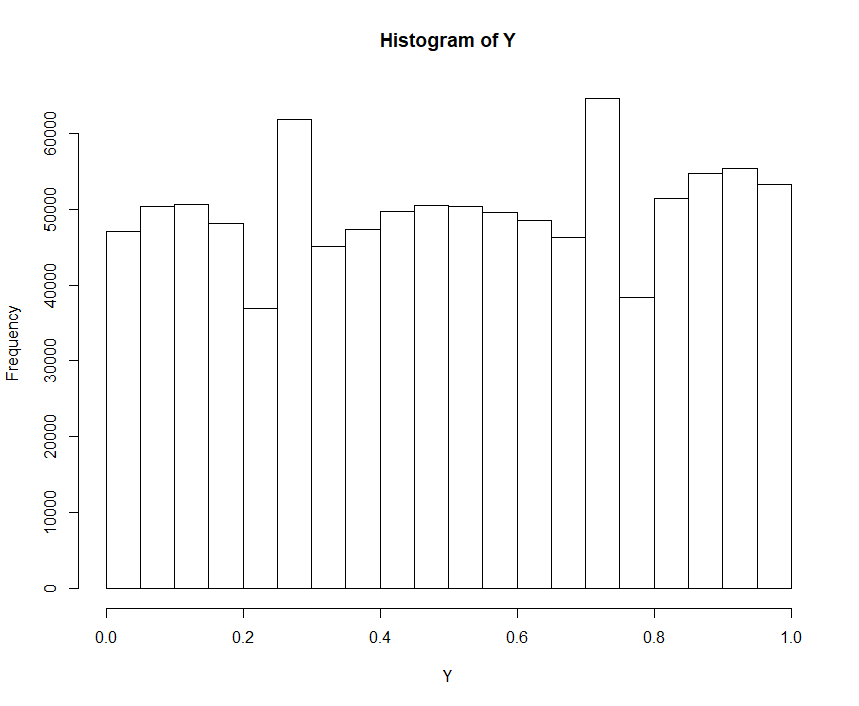
 with size set to
with size set to 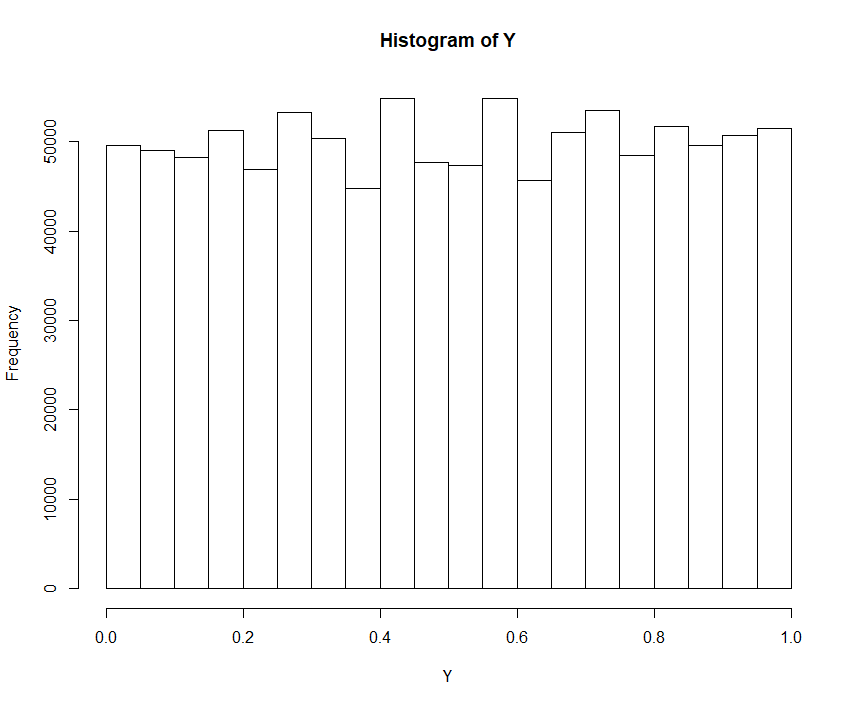 with size set to
with size set to 
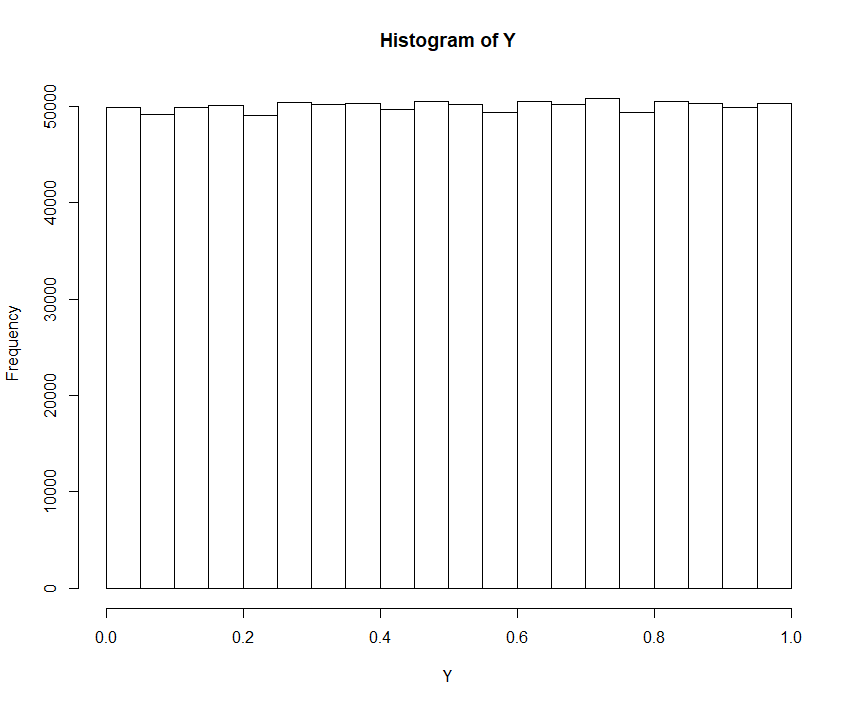 with size set to
with size set to
That is, if a discrete distribution either converges close enough to a continuous distribution or if the discrete distribution has even jumps (i.e. discrete uniform) then the corresponding histogram of  will show a similar pattern as described in Theorem I.
will show a similar pattern as described in Theorem I.
In addition, note that all continuous distributions need to be discretized due to the limitations of a computer.
Quantile Function Theorem
A relative of the Probability Integral Transform is the Quantile Function Theorem. However, this time we do not get an uniform sample / distribution as a result but we start with one. Hence, let us now draw a large uniformly distributed sample  . We use R to perform the simulation.
. We use R to perform the simulation.
U <- runif(n=10^6, min=0, max=1) hist(U)
Starting off with an uniformly distributed sample , we need to “invert” the steps performed to illustrate the Probability Integral Transform Theorem. That is, we now have to apply the generalized inverse distribution function of the intended distribution and apply to it.
If we would like to receive the standard normal distribution, for instance, needs to be fed into the following generalized inverse  –shown in Fig. 8– of the Standard Normal distribution.
–shown in Fig. 8– of the Standard Normal distribution.
Be aware that a generalized inverse does in general not equal an inverse function since a (discrete) distribution function might contain flat parts of its graph. The distribution function of the Standard Normal distribution is continuous and its (generalized) inverse is depicted in Fig. 8.
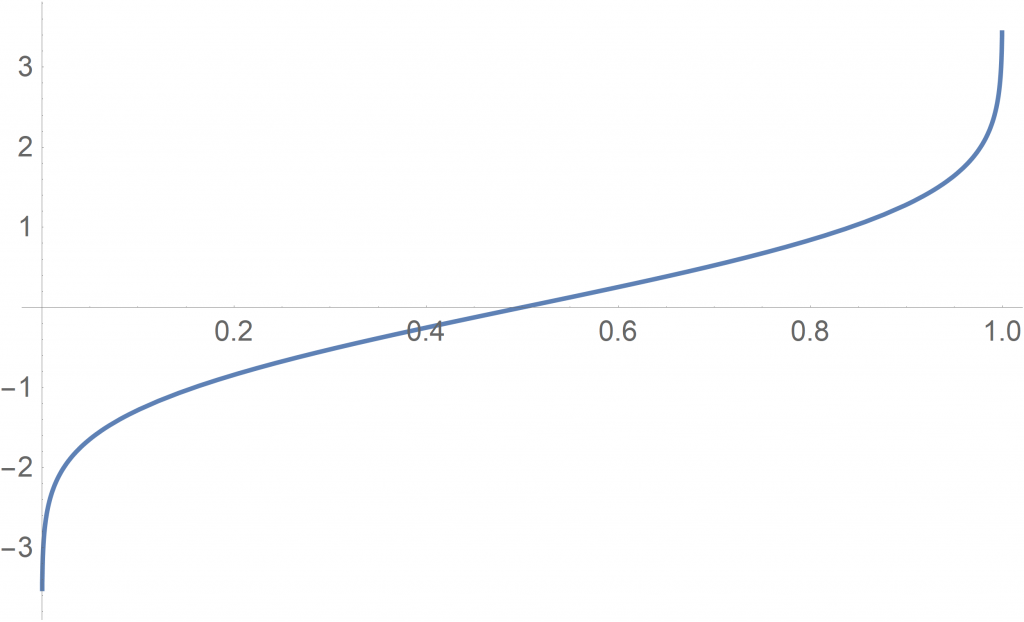 of distribution function of Standard Normal distribution
of distribution function of Standard Normal distributionTake a while and think about what the function actually does — it takes a probability in  and assigns it to a real value. For instance, the probability 0.5 is assigned to the real value 0. Values in the left tail of the distribution get a rather small absolute numbers (i.e. a value close to 0) while values in the right tail get a number very close to 1. That is, the increase in probability is quite small in the tails, which is in line with the nature of a normal distribution.
and assigns it to a real value. For instance, the probability 0.5 is assigned to the real value 0. Values in the left tail of the distribution get a rather small absolute numbers (i.e. a value close to 0) while values in the right tail get a number very close to 1. That is, the increase in probability is quite small in the tails, which is in line with the nature of a normal distribution.
In R we need to take the following steps:
X <- qnorm(U, mean=0, sd=1) hist(X)
The histogram of , as shown in Fig. 9, is governed by the standard normal distribution. Just as desired.
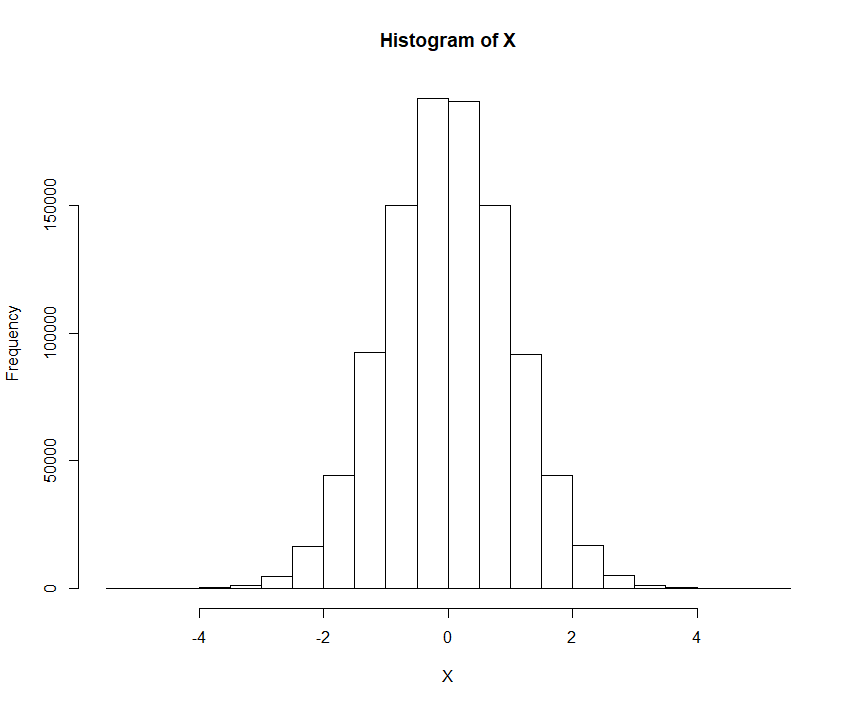

Again, please note that the inverse distribution function does not necessarily mean the inverse function. Distribution functions are in general not strictly increasing but non-decreasing. For further details we highly recommend P. Embrecht’s & M. Hofert’s paper ‘A note on generalized inverses’. The difference between inverse and generalized inverse functions will also play a key role in the proof of the Probability Integral Transformation Theorem.
In addition, Theorem II (Quantile Function) does NOT require the distribution function to be continuous. At first sight, this might seem strange since the Quantile Function Theorem is just a kind of inversion of the other.
Example 3 (Binomial Variable)
Let us continue the Binomial example (see above) with respect to the Quantile Function Theorem. We draw an uniformly distributed large sample and put it into the generalized inverse distribution function ![G_X^{-1}:[0,1] \rightarrow \mathbb{R}](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-232cdf2c94278df373ade695c66fc644_l3.png "Rendered by QuickLaTeX.com") of with and . The graph of the corresponding quantile function is illustrated in Fig. 10.
of with and . The graph of the corresponding quantile function is illustrated in Fig. 10.
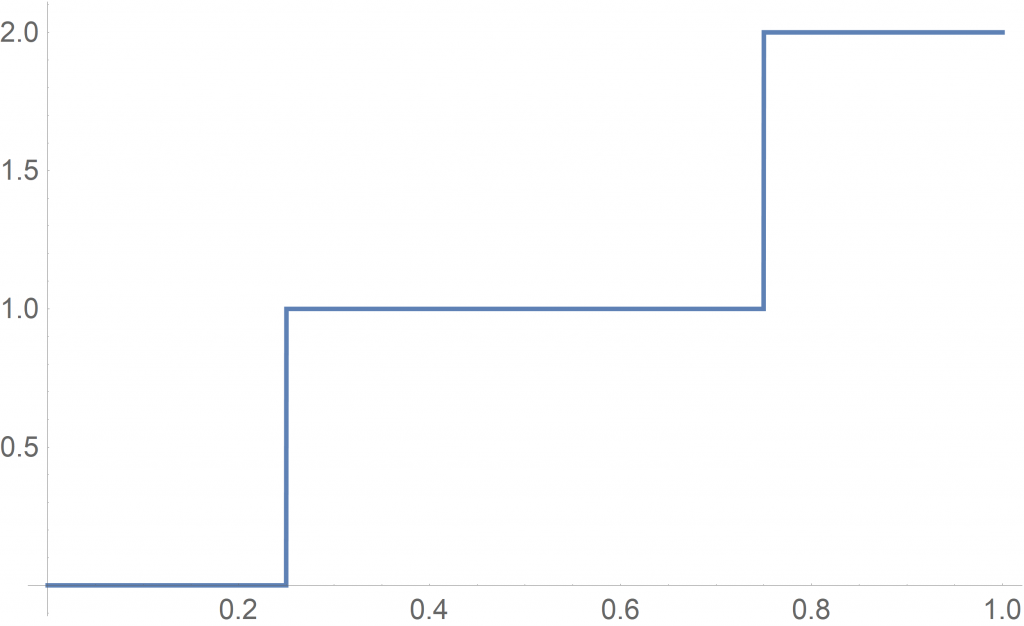 with
with 
Again, let us take the time to think about the meaning of this generalized inverse (i.e. quantile function) of the Binomial (cumulative) distribution function. It assigns an integer to each probability in . In our example, it assigns the integer to the probabilities  , the integer to the probabilities
, the integer to the probabilities  and to the probabilities
and to the probabilities ![[0.75,1]](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-ec0f0badc7648a913a79dd38d72793e0_l3.png "Rendered by QuickLaTeX.com") .
.
Let us do this in R:
U <- runif(n=10^6, min=0, max=1) hist(U) X <- qbinom(U, size=2, prob = 0.5) hist(X)
The result –depicted in Fig. 11– is as expected.
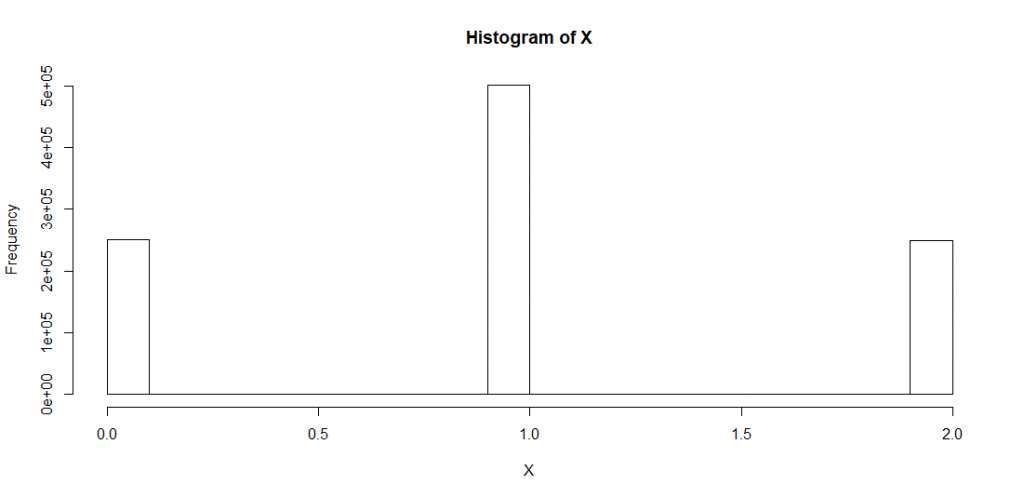
 that is distributed according to
that is distributed according to 
Apparently, we have received the desired Binomial distribution by first generating a standard uniform sample and then applying the quantile function to it.
Proofs
This section is based on the paper [1.] by John E. Angus. The problem with the usual attempts to prove the Probability Integral Transformation Theorem is, that it is often not made clear how an inverse of a distribution function can be achieved. Please also refer to this post on StackExchange. For instance, the proof provided on Wikipedia is as follows:
<< Given any random continuous variable , define  . Then:
. Then:

 is just the CDF of a Uniform(0,1) random variable. Thus, has a uniform distribution on the interval . >>
is just the CDF of a Uniform(0,1) random variable. Thus, has a uniform distribution on the interval . >>
Wikipedia retrieved in Nov. 2020.
The cited “proof” above seems to be quite straight-forward. However, it is not clarified what is meant by applying the “inverse”  . In the next subsection we are going to learn more about that step in Lemma 1.
. In the next subsection we are going to learn more about that step in Lemma 1.
Some textbooks require that a ‘strictly increasing distribution function/random variable’ is needed to apply the Probability Integral Transform Theorem even though continuity is sufficient. Again, please refer to this post on StackExchange.
Probability Integral Transformation
The following lemma is the key to the proof of Theorem I. The principle idea is that the basic set can be decomposed into  , where
, where  stands for the disjoint union.
stands for the disjoint union.
In addition, recall that a distribution function is monotone: if  , we have
, we have  .
.
Lemma 1:
Let have a distribution function . Then for all real the following holds:
 .
.
Proof of Lemma 1:
Decompose the event  as follows:
as follows:
![\begin{align*}&\{\omega: F(X(\omega)) \leq F(x) \} \\&= \left[ \{\omega: F(X(\omega)) \leq F(x) \} \cap \{\omega: X(\omega) \leq x \} \right] \sqcup \\&\left[ \{\omega: F(X(\omega)) \leq F(x) \} \cap \{ X(\omega) > x \} \right]\end{align*}](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-c83667ae5fe106fb7447e890ff7c10f9_l3.png "Rendered by QuickLaTeX.com")
Note that  since is monotone. In addition,
since is monotone. In addition,  . Again, due to the monotonicity of we see that
. Again, due to the monotonicity of we see that  . Hence, the intersection
. Hence, the intersection  is empty. Considering these facts, we can derive
is empty. Considering these facts, we can derive
(1) ![\begin{align*} & \{\omega: F(X(\omega)) \leq F(x) \} \\&= \{\omega: X(\omega) \leq x \} \sqcup \\& \ \left[ \{ \omega: X(\omega) > x \} \cap \{ \omega: F(X(\omega)) = F(x) \} \right].\end{align*}](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-f3e2ab34cd0d2e7780d8c0d5b961b6c3_l3.png "Rendered by QuickLaTeX.com")
Taking probabilities in  , the assertion follows since the event
, the assertion follows since the event  has zero probability.
has zero probability.
Example 4 (Binomial Variable)
Let us re-consider the discrete variable  as treated in Example 1 to 3. Recall that we denote the distribution function of the discrete random variable by . Let us further denote the basic set, that represents the outcome of the Bernoulli trials, by . is defined by
as treated in Example 1 to 3. Recall that we denote the distribution function of the discrete random variable by . Let us further denote the basic set, that represents the outcome of the Bernoulli trials, by . is defined by  number of successes. We therefore have
number of successes. We therefore have
![\begin{align*} & \{ \omega: G_X(X(\omega)) \leq G_X(k) \} \\ &= \{ \omega: X(\omega) \leq k \} \sqcup \\ & \ \left[ \{ \omega: X(\omega) > k \} \cap \{ \omega: G_X(X(\omega)) = G_X(k) \} \right] \\&= \ \{ \omega: X(\omega) > k \} \end{align*}](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-bd473912d6f1e958f6d17ddb7fa48138_l3.png "Rendered by QuickLaTeX.com")
with  . In order to further illustrate that, let us consider the set
. In order to further illustrate that, let us consider the set  for
for  . The resulting set
. The resulting set  (failure, failure)
(failure, failure) has empty intersection with
has empty intersection with  (failure,success)
(failure,success) (success,failure)(success,success).
(success,failure)(success,success).
Let us ultimately prove the Probability Integral Transformation Theorem.
Proof Theorem I (Probability Integral Transformation):
Let  . Since is continuous, there exist a real
. Since is continuous, there exist a real  such that
such that  . Then by Lemma 1,
. Then by Lemma 1,  , which implies that is governed by .
, which implies that is governed by .
Quantile Function Transformation
Proof Theorem II (Quantile Function Theorem):
First, suppose that  . Note that for any such that
. Note that for any such that  and any ,
and any ,  if, and only if,
if, and only if,  .
.
Suppose that  , then
, then  is an infinite interval that contains its left-hand endpoint since is non-decreasing and right-continuous.
is an infinite interval that contains its left-hand endpoint since is non-decreasing and right-continuous.
Conversely, suppose that  , then
, then  . It follows now that
. It follows now that  , completing the proof.
, completing the proof.
Generating Normally Distributed Samples in Excel
Given the explanations above, it is quite obvious how to generate normally distributed samples in Microsoft Excel. What we need are the following ingredients in Excel:
- Uniformly distributed samples provided in Excel by
RAND(); - Generalized inverse of the standard normal distribution provided in Excel by
NORM.S.INV(probability);
According to the Quantile Function Theorem, the outcome will be a standard normally distributed sample.
In the first step, we need to generate an uniformly distributed sample by including the formula RAND() in as many cells as we would like to have samples. Then, by filling the formula NORM.S.INV(probability) in corresponding cells the uniformly distributed value is transformed to a standard normally distributed value as illustrated in Fig. 13. Note that the formula NORM.S.INV(probability) is the generalized inverse function of the standard normal distribution.
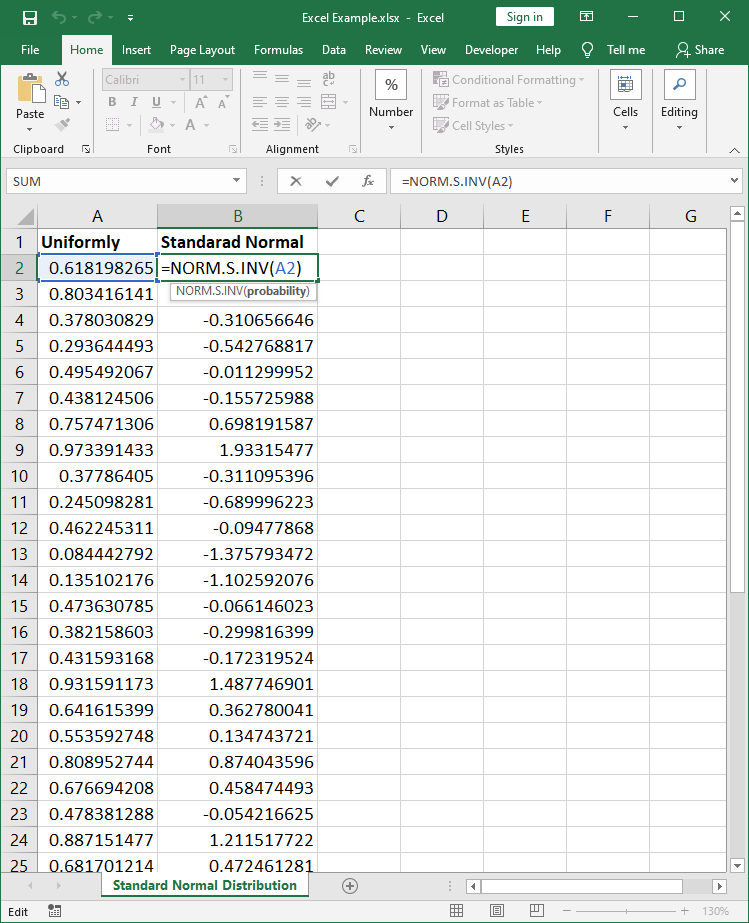
NORM.S.INV(probability)We could also use the formula NORM.INV(probability, mean, standard deviation) in order to generate any other normal distribution. Refer to Fig. 14 for an additional illustration.
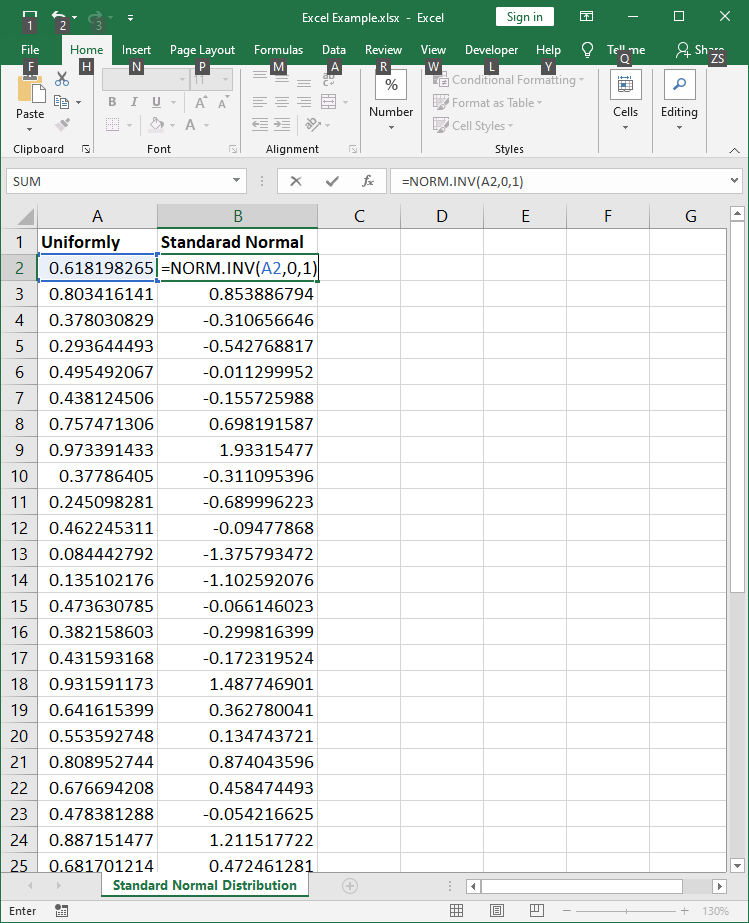
NORM.INV(probability, mean, standard deviation)According to Microsoft the following list of statistical functions is available. All inverse distribution functions can be used to generate a corresponding sample.
Given that continuity is not needed to apply the Quantile Function Theorem, we can also generate discretely distributed samples by applying the same simple algorithm as outlined in the continuous case.
Multivariate Case & Copulas
This section serves as an outlook on the application of both treated theorems to copulas. It is therefore a perfunctory treatment of the topic. Nonetheless, it will become clear how the Probability Integral Transform is used to define copulas.
First, we need some basic notation for the multivariate case: Let  denote the dimension of the considered Euclidean vector space
denote the dimension of the considered Euclidean vector space  . We define a multivariate random variable or random vector
. We define a multivariate random variable or random vector  as multivariate measurable function. A
as multivariate measurable function. A  -interval is the Cartesian product of real intervals and a -box is a closed -interval. The unit -cube
-interval is the Cartesian product of real intervals and a -box is a closed -interval. The unit -cube ![[0,1]^d](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-cd30dbe72b6c473cdbd3c79edd598f5b_l3.png "Rendered by QuickLaTeX.com") is the -box denoted by
is the -box denoted by ![[0,1]^d = [(0, \ldots, 0), (1, \ldots, 1)]](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-0cde38253067b9c778c9ed958efc70c4_l3.png "Rendered by QuickLaTeX.com") .
.
For continuous multivariate distributions, the univariate marginals along with a dependency structure called copula, can be separated. If we apply the Probability Integral Transformation Theorem to a given random vector  to each component, we get a multivariate distribution
to each component, we get a multivariate distribution
(2) 
with uniform marginals  ,
,  reflecting the exposed dependency structure. This motivates the following definition of a copula.
reflecting the exposed dependency structure. This motivates the following definition of a copula.
Let be a probability space and its distribution function. For every  , a -dimensional copula of is the joint -dimensional distribution function
, a -dimensional copula of is the joint -dimensional distribution function ![C:[0,1]^d \rightarrow [0,1]](https://www.deep-mind.org/wp-content/ql-cache/quicklatex.com-0faaffea30f3525d6200cef397fb0306_l3.png "Rendered by QuickLaTeX.com") defined by
defined by
(3) 
Copulas embody the way in which multidimensional distribution functions are coupled to their 1-dimensional margins. By applying the Probability Integral Transform to each component of a random vector as denoted in (2), its multivariate dependency structure can be exposed. Please also note that the Quantile Function Theorem can also be used to simulate copulas.