
Most people do have an intuitive understanding of the real number system: it is the number system that should be used for measurements of space and time as well as for other physical quantities that are thought of as varying continuously rather than discretely. This number system is also the basis for the modern understanding of geometrical concepts such as length, distance and angle. On the other hand, inner products, norms and metrics are needed for fundamental topics such as convergence, continuity and several concepts within topology.
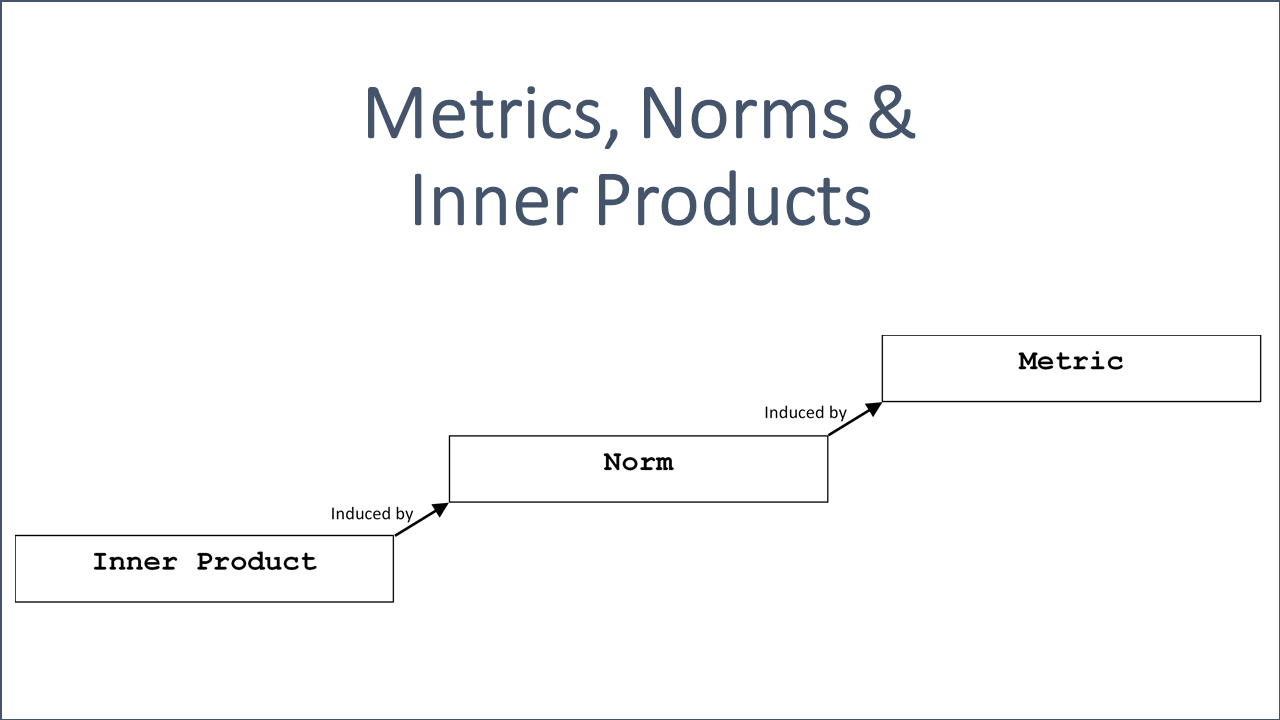
Hence, the overall objective of this blog post is to foster the intuition, to explain the motivation behind and the interrelation between inner products, norms and metrics of inner products. All three function types are closely related to each other since an inner product can induce a norm, which itself can ultimately induce a corresponding metric.
Metrics are nothing but distance functions just like a reasonable person would imagine. A norm can also geometrically be interpreted as the distance of a real-valued point (e.g. in the Euclidean plane) to the origin measured via a corresponding distance function (, that can be induced by this norm). The interpretation of inner product is not that obvious, but one can see dot-products as something like a measure of how similar two vectors are. There are also helpful animated illustration of 3Blue1Brown and Zach Star (links below).

All three function types life in a vector space. We assume the reader knows the basics about vector spaces. A rather short introduction to Euclidean vector spaces is provided, though.
Euclidean Spaces
It might turn out to be quite helpful to recall the basic knowledge about vector spaces. A very good overview is provided by the following videos of PacoVideoLectures:
Ok, now that we have recalled the basics of vector spaces let us go back to Euclidean spaces. A point  in the 2-dimensional plane can be modeled as an ordered pair
in the 2-dimensional plane can be modeled as an ordered pair  of real numbers. Similarly, a point in a 3-dimensional space can be interpreted as an ordered triple
of real numbers. Similarly, a point in a 3-dimensional space can be interpreted as an ordered triple  of real numbers. In general, we consider a set of
of real numbers. In general, we consider a set of  -tuples
-tuples  of real numbers. Usually, these type of vectors are column vectors.
of real numbers. Usually, these type of vectors are column vectors.
Let  and
and  be in
be in  . We define equality
. We define equality  if, and only if,
if, and only if,  ,
,  ,
,  . The sum
. The sum  and the difference
and the difference  are component-wise, that is,
are component-wise, that is,  . The multiplication by real numbers
. The multiplication by real numbers  (also called scalars) is defined by
(also called scalars) is defined by  .
.
In modern terms, an Euclidean space is a vector space equipped with an “inner product”. Actually, an Euclidean space is simply a space of classical geometry. In any case, we need to define what an inner product actually is.
Inner Products
An inner product  , also called dot product, is a function that enables us to define and apply geometrical terms such as length, distance and angle in an Euclidean (vector) space
, also called dot product, is a function that enables us to define and apply geometrical terms such as length, distance and angle in an Euclidean (vector) space  .
.
Please recall that metrics (distance functions) can be induced by inner products.
Definition 2.1:
Let  be a vector space over
be a vector space over  . An inner product on is a function
. An inner product on is a function  such that for all
such that for all  and
and  , the following hold:
, the following hold:
 and
and  ;
; ;
; .
.
Inner products can be generally defined as a symmetric bilinear form and a bilinear form is a bivariate functions that is linear with respect to each isolated argument. Note that the above definition can be generalized to complex vector spaces employing sesquilinear forms. We, however, restrict ourselves to real vector spaces and to the consideration of the standard inner product as defined in the following example.
Example 2.1:
The so-called standard inner product or Euclidean inner product of the real vector space is defined by  for
for  . Please convince yourself that this function actually fulfills the required properties.
. Please convince yourself that this function actually fulfills the required properties.

For  and
and  we get
we get  =
= =
= .
.
Note that you can also use matrix multiplication to define the Euclidean inner product. For instance, if you have  , then
, then  =
= . Note that the last term of the equation shows a matrix multiplication of a 1-times-2 and a 2-times-1 matrix.
. Note that the last term of the equation shows a matrix multiplication of a 1-times-2 and a 2-times-1 matrix.
An interpretation of inner products is not that obvious. An inner product basically provides a meausre of how similar the two input vectors are.
A geometric illustration of dot products is explained by 3Blue1Brown. While watching bear in mind that an inner product is a symmetric bilinear form.
If you are interested in the duality of vector spaces, refer to this article (in German).
There is also another nice video of applications of inner products by Zach Star:
It might also help to learn (more) about norms and metrics. Knowing that inner products, norms and metrics are closely related to each other means that understanding one concept provides also heuristic information about the other concept.
Finally, another very nice video about the (mathematical) application of the inner product.
Norms
Functions closely related to inner products are so-called norms. Norms are specific functions that can be interpreted as a distance function between a vector and the origin.
Definition 3.1:
Let be a real vector space over . A function  with
with  is called norm, and,
is called norm, and,  is called normed space if for all
is called normed space if for all  the following holds true:
the following holds true:
(i)  if
if  (positivity);
(positivity);
(ii)  for all
for all  (homogenity);
(homogenity);
(iii)  (triangle inequality).
(triangle inequality).
Properties (ii) and (iii) make only sense over a vector space. The former property is stating how the scalar product of a vector and a field element needs to behave to be a valid norm function.
An example will help to clarify what a norm function is.
Example 3.1:
(a) Let  defined by
defined by  the absolute value, that is a norm over the one-dimensional real vector space. It is always positive and only zero if
the absolute value, that is a norm over the one-dimensional real vector space. It is always positive and only zero if  and it also fulfills homogenity by definition.
and it also fulfills homogenity by definition.
To see that the triangle inequality (also called subadditivity) holds, first bear the definition of the absolute value in mind. If  and
and  as well as
as well as  then
then  . In addition,
. In addition,  ,
,  as well as
as well as  ,
,  hold true. Hence, by adding both inequalities we get
hold true. Hence, by adding both inequalities we get  as well as
as well as  , as desired.
, as desired.
(b) Let  ,
,  defined by
defined by  , which is called Euclidean norm. Note that
, which is called Euclidean norm. Note that  is the Euclidean inner product as defined in Example 2.1.
is the Euclidean inner product as defined in Example 2.1.
If the Euclidean norm  can be interpreted as the length between the origin and the vector
can be interpreted as the length between the origin and the vector  , then the Euclidean inner product
, then the Euclidean inner product  can be interpreted as the squared norm
can be interpreted as the squared norm  .
.
Example (a) is actually the most important example of a norm since basically every practically important norm can be traced back to the absolute value function in some sense.
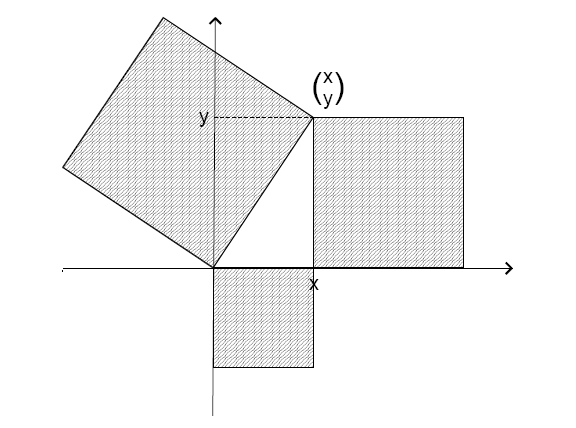
The Euclidean norm of the vector  equals
equals  , which is exactly the length of hypotenuse of the corresponding triangle in Figure 2. That is, the Euclidean norm equals the distance between the origin and the point
, which is exactly the length of hypotenuse of the corresponding triangle in Figure 2. That is, the Euclidean norm equals the distance between the origin and the point  in the Euclidean plane, which can also be derived from Pythagorean’s theorem. It also explains why the property (iii) is called triangle property ( and sometimes also subaditivity).
in the Euclidean plane, which can also be derived from Pythagorean’s theorem. It also explains why the property (iii) is called triangle property ( and sometimes also subaditivity).
The norm  is also called distance between the two real-valued vectors and
is also called distance between the two real-valued vectors and  . The angle
. The angle  between two vectors and with
between two vectors and with  is defined by
is defined by  . This naturally leads us to the definition of another closely related function type.
. This naturally leads us to the definition of another closely related function type.
Metrics
Let us directly define the important term metric.
Definition 4.1:
Let be a real vector space over . A function  is called metric or distance function on , and,
is called metric or distance function on , and,  a metric space, if for all
a metric space, if for all  the following holds true:
the following holds true:
(i)  and
and  if and only if ;
if and only if ;
(ii)  ;
;
(iii)  .
.
Based on a day-to-day experience, the following basic considerations are reflected in (i) to (iii) of the definition of a metric:
- Distances between two points can be represented by a positive real number;
- Distances are independent from the order of measuring. That is, the distance between two points is always the same no matter at what point you start to measure;
- Detours will imply longer distances.
Hence, the definition of a metric is nothing but an abstraction of the main features of a reasonable distance concept.
Example 4.1:
Consider  defined by
defined by  , whereby
, whereby  is the absolute value. The function
is the absolute value. The function  is a metric since the absolute value is always positive and
is a metric since the absolute value is always positive and  if and only if . Also (ii) is obvious. Property (iii), also called sub-additivity or triangle property, can be shown by distinguishing several cases. For more details reg. the properties of the absolute value function please refer to the corresponding wiki article.
if and only if . Also (ii) is obvious. Property (iii), also called sub-additivity or triangle property, can be shown by distinguishing several cases. For more details reg. the properties of the absolute value function please refer to the corresponding wiki article.
Topological features do play a big role in mathematical analysis as it is together with measure theory the foundation of how things can be measured. By using the norm and/or distances, we could also define topological terms such as open sets or balls.
Definition 4.2: Let  be a metric space and
be a metric space and  . Furthermore, let
. Furthermore, let  ,
,  .
.
(i) The set  is called
is called  –ball of
–ball of  in .
in .
(ii) Let  . The set
. The set  is called neighborhood of in if there is an such that
is called neighborhood of in if there is an such that  .
.
Probably the most prominent family of metric spaces is  , where
, where  is defined as
is defined as
(1) 
with  and
and  . The case
. The case  of the
of the  metrics is the absolute value as outlined in Example 3.1. The corresponding normed spaces
metrics is the absolute value as outlined in Example 3.1. The corresponding normed spaces  can be defined as follows:
can be defined as follows:
(2) 
 is directly connected to the corresponding metric spaces
is directly connected to the corresponding metric spaces  via
via  .
.
norms and metricsIf is a metric space, then  with
with  is also a metric space. The necessary properties are transmitted to the sub-space simply by remembering the distances between two arbitrary points
is also a metric space. The necessary properties are transmitted to the sub-space simply by remembering the distances between two arbitrary points  . The metric is also called metric induced by .
. The metric is also called metric induced by .